Linux 모니터링 시 사용 명령어 10가지
1. uptime
- 평균 부하 확인
- 구동하고자 하는 task-프로세스 개수 확인
- CPU, I/O 포함
- 1/5/15분 평균 값)

2. dmesg | tail
- 최근 10 개 시스템 메시지 확인

3. vmstat 1
- 초 간 가상 메모리 stat; 첫번째 라인은 부팅 후 평균 값 나타내니 무시할 것
- r : CPU 구동 중 프로세스 수; I/O 미포함; CPU 값보다 클 경우 포화임을 나타냄
- free : free 메모리(kb)
- si,so : Swap-ins & swap-outs; 0가 아닐 경우 메모리 부족
- us, sy, id, wa, st : CPU 시간를 분리하여 나타낸 부분 (user time, system time (kernel), idle, wait I/O, stolen time)

4. mpstat -P ALL 1
- CPU 당 CPU 시간 세분 확인

5. pidstat 1
- top의 프로세스 별 확인

**위 예시에서는 java가 1591% CPU를 사용한다고 나타남. 이럴 경우 거의 16 CPU 사용 중인걸 알 수 있음
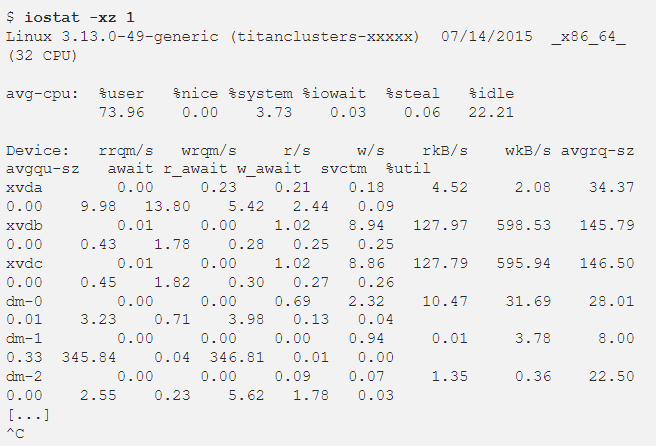
6. iostat -xz 1
- 블록 디바이스(disk) 확인 가능
- 적용된 워크로드, 결과적 성능 확인
- 논리적인 디스크는 100%에 가까울수록 포화상태일 확률이 높으나 백앤드 디스크일 경우 더 많은 사용률 수용 가능
- Read ahead for reads, buffering for writes 등 I/O를 비동기적으로 하게 하여 디스크 부하를 줄일 수 있다
- r/s, w/s, rkB/s, wkB/s : 디바이스 당, 초 당 전달된 reads, writes, 그리고 read Kbytes, write Kbytes; 워크로드 성격 확인 가능
- await : 밀리초당 평균 I/O; 어플리케이션에 부하가 있는지 확인 가능
- avgqu-sz : 디바이스 당 평균 요청; 1보다 클 경우 포화
- %util : 디바이스 사용률; 60% 이상일 경우 성능 저하(디바이스에 따라 상이)
7. free -m
- 사이즈가 0과 가까울수록 안좋음. 높은 디스크 I/O와 성능 저하 가능(iostat으로 확인 가능)
- buffers : 블록디바이스 I/O를 위한 버퍼 캐시
- cached : 파일 시스템을 위한 페이지 캐시를
- -/+ buffers/cache : 캐시를 위한 캐시 메모리

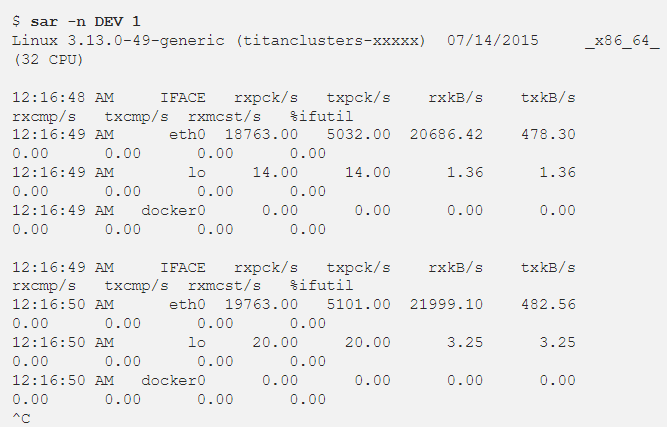
8. sar -n DEV 1
- 네트워크 인터페이스 throughput 확인(rxkB/s, txkB/s)
9. sar -n TCP,ETCP 1
- TCP 지표 확인
- 서버 로드 대강 확인 가능
- active/s : 초당 로컬 실행 TCP 연결 (ex. via connect()); 신규 연결 개수
- passive/s : 초당 리모트 실행 TPC 연결 (ex. via accept()); 다운스트림 연결 개수
- retrans/s : 초당 TCP 재전송; 퍼블릭 인터넷 등 unreliable 네트워크 연결일 수 있음; 서버가 트래픽 과부화로 패킷 드롭 중일수도..

10. top
- 부하 변수 확인
- 확인 어려울 경우 롤링 아웃풋 제공하는 vmstat, pidstat 등 활용
- Ctrl-S(pause), Ctrl-Q (continue)
